Before talking about new stuff in C# and .NET Framework overall, it would be good to see how the platform evolved over the time (e.g. since the first release in 2002). A lot has been changed since, meaning that .NET became platform-agnostic and very mature platform for Enterprise-grade software development.
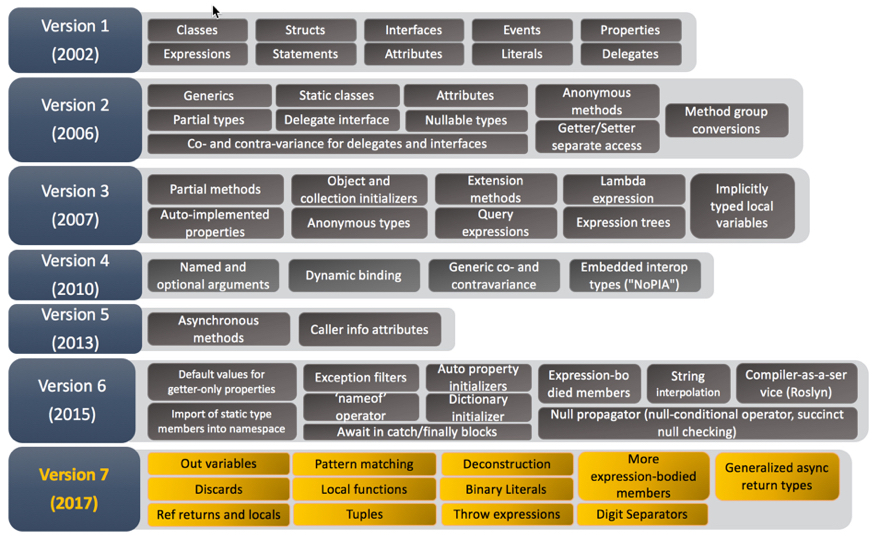
Figure 1. C# Language evolution
As you see from the scheme, every version brought something really exciting. Along with new features and .NET Core appearance, it also triggered certain confusion in versioning, platform/framework names, framework’s capabilities, etc. We’ll clarify what all this is all about first in the second part of this topic. Let’s start with the interesting part.
Part 1. C# ver.7 and the future prospect
Binary Literals
Numeric literals are not a new concept in C#. We have been able to define integer values in base-10 and base-16 since C# was first released. Common uses case for base-16 (also known as hexadecimal) literals is to define flags and bit masks in enumerations and constants. Since each digit in a base-16 number is 4 bits wide, each bit in that digit is represented by 1, 2, 4, and 8.
While this is familiar to most, using C#7 we can now express such things explicitly in base-2, more commonly referred to as binary. While hexadecimal literals are prefixed with 0x , binary literals are prefixed with 0b:
const int MyValue = 0b00_00_11;
Local functions
Those who are familiar with JavaScript will be familiar with local functions; the ability to define a method inside of another method. We have had a similar ability in C# since anonymous methods were introduced albeit in a slightly less flexible form1. Up until C#7, methods defined within another method were assigned to variables and were limited in use and content. Local functions allow us to declare a method within the scope of another method; not as an assignment to a run-time variable as with anonymous methods and lambda expressions, but as a compile-time symbol to be referenced locally by its parent function:
private static void UseLocalFunction()
{
uint Collatz(uint value) => value % 2 == 1 ? (3 * value + 1) / 2 : value / 2;
}
‘Out’ variables
How often have you written code like this?
int dummy;
if (int.TryParse(someString, out dummy) && dummy > 0)
{
//TODO
}
Meaning that typically with ‘out’ variables you need to declare the variable first, then pass it into the method. Now you can do that all in one line:
if (int.TryParse(value, out var thirdWay))
‘Out’ variables are part of a wider set of features for reducing repetition (in written code and in run-time execution), and saying more with less (i.e. making it easier for us to infer intent from the code without additional commentary). This is a very simply addition to C# syntax, yet useful.
Tuples and deconstruction
Tuples are a temporary grouping of values. You could compare a Tuple to a POCO-class, but instead of defining it as a class you can define it on the fly. The following is an example of such a class:
class MyProperty
{
public int Id {get; set;}
public string Name {get; set;}
}
var myObj = new PropertyBag { Id = 1, Name = "test};
In the above example it wasn’t really necessary to name the concept we’re working with as it is probably a temporary structure that doesn’t need naming. Tuples are a way of temporarily creating such structures on the fly without the need to create classes. The most common reason for having a group of values temporarily grouped are multiple return values from a method. Currently, there are a few ways of doing that in C#: out-parameters, tuple-type, class/struct. All these approaches have certain variables (please refer to the previous paragraph to read about out-parameter for example).
You can specify multiple return types for a function, in much the same syntax as you do for specifying multiple input types (method arguments):
public (double lat, double lng) GetLatLng(string address) { ... }
var ll = GetLatLng("some address");
Console.WriteLine($"Lat: {ll.lat}, Long: {ll.lng}");
NOTE: You need to reference System.ValueTuple for Tuples to work. You can also turn an object into a tuple if it implements Deconstruct().
Pattern matching
As we’ve seen so far, C# 7.0 introduces some nice new things, like "out" variables and binary literals. These are all great little additions, but it has truly cool and long-awaited features in its arsenal, like pattern matching.
I can admit that I was a bit confused as to why this is called "pattern matching." I read the Wikipedia article and expected to understand this more if I were a Computer Science major instead of Computer Systems Engineering. According to Wikipedia:
“In computer science, pattern matching is the act of checking a given sequence of tokens for the presence of the constituents of some pattern.”
The What's New in C# 7 documentation explains:
“Pattern matching is a feature that allows you to implement method dispatch on properties other than the type of an object”.
Well, this is a bit confusing, isn’t it? In my understanding “Pattern matching” means that you can switch on the type of data you have to execute one or the other statement. Although pattern matching looks a lot like if/else, it has certain advantages:
- You can do pattern matching on any data type, even your own, whereas if/else you always need primitives to match
- Pattern matching can extract values from your expression
In C# 7.0 we are enhancing two existing language constructs with patterns:
- is expressions can now have a pattern on the right hand side, instead of just a type
- case clauses in switch statements can now match on patterns, not just constant values
In future versions of C# we are likely to add more places where patterns can be used.
The following is an example of pattern matching:
class Geometry();
class Triangle(int Width, int Height, int Base) : Geometry;
class Rectangle(int Width, int Height) : Geometry;
class Square(int width) : Geometry;
Geometry g = new Square(5);
switch (g)
{
case Triangle(int Width, int Height, int Base):
WriteLine($"{Width} {Height} {Base}");
break;
case Rectangle(int Width, int Height):
WriteLine($"{Width} {Height}");
break;
case Square(int Width):
WriteLine($"{Width}");
break;
default:
WriteLine("<other>");
break;
}
In the sample above you can see how we match on the data type and immediately de-structure it into its components.
Ref Locals and Ref Returns
C#7 brings a variety of changes to how we get output from the methods, specifically, out variables, tuples, and ref locals and ref returns. We’ve already covered “out” in this topic, so let's take a look at ref locals and ref returns. Like the changes to async return types, this feature is all about performance.
NOTE: The addition of ref locals and ref returns enable algorithms that are more efficient by avoiding copying values, or performing dereferencing operations multiple times.
Like many performance-related issues, it is difficult to come up with a simple real-world example that is not entirely contrived. So, suspend your engineering minds for a moment and assume that this is a perfectly great solution to the problem at hand so that I can explain this feature to you. Imagine it is Halloween and we are counting how many pieces of candy we have collectively from all of our heavy bags of deliciousness. We have several bags of candies with different candy types and we want to count them. So, for each bag, we group by candy type, then retrieve the current count of each candy type, add the count of that type from the bag, and then store the new count:
void CountCandyInBag(IEnumerable<string> bagOfCandy)
{
var candyByType = from item in bagOfCandy
group item by item;
foreach (var candyType in candyByType)
{
var count = _candyCounter.GetCount(candyType.Key);
_candyCounter.SetCount(candyType.Key, count + candyType.Count());
}
}
class CandyCounter
{
private readonly Dictionary<string, int> _candyCounts = new Dictionary<string, int>();
public int GetCount(string candyName)
{
if (_candyCounts.TryGetValue(candyName, out int count))
{
return count;
}
else
{
return 0;
}
}
public void SetCount(string candyName, int newCount)
{
_candyCounts[candyName] = newCount;
}
}
This example works just fine, but it has an overhead; we have to look up the candy count value in our dictionary multiple times when retrieving and setting the count. However, by using ref returns, we can create an alternative to our dictionary that minimizes that overhead. However, we also cannot use a local variable as we cannot return a reference to a value that does not live beyond the method call, so we must modify how we store our counts:
void CountCandyInBag(IEnumerable<string> bagOfCandy)
{
var candyByType = from item in bagOfCandy
group item by item;
foreach (var candyType in candyByType)
{
ref int count = ref _candyCounter.GetCount(candyType.Key);
count += candyType.Count();
}
}
class CandyCounter
{
private readonly Dictionary<string, int> _candyCountsLookup = new Dictionary<string, int>();
private int[] _counts = new int[0];
public ref int GetCount(string candyName)
{
if (_candyCountsLookup.TryGetValue(candyName, out int index))
{
return ref _counts[index];
}
else
{
int nextIndex = _counts.Length;
Array.Resize(ref _counts, nextIndex + 1);
_candyCountsLookup[candyName] = _counts.Length - 1;
return ref _counts[nextIndex];
}
}
}
Now we are returning a reference to the actual stored value and changing it directly without repeated look-ups on our data type, making our algorithm performing better. Be sure to check out the official documentation for alternative examples of usage.
NOTE: I want to take a moment to point out a few things about the syntax. This feature uses the ref keyword a lot. You have to specify that the return type of a method is ref, that the return itself is a return ref, that the local variable storing the returned value is a ref, and that the method call is also ref. If you skip one of these uses of ref, the compiler will let you know, but as I discovered when writing the examples, the message is not particularly clear regarding how to fix it. Not only that, but you may get caught out when trying to consume by-reference returns as you can skip the two uses at the call-site. e.g.:
int count =_candyCounter.GetCount(candyName);
in such a case, the method call will be as if it were a regular, non-reference return, so, watch out!
Generalized async return types
Returning a Task object from async methods can introduce performance bottlenecks in certain paths. "Task" is a reference type, so using it means allocating an object. In cases where a method declared with the async modifier returns a cached result or completes synchronously, the extra allocations can become a significant time cost in performance-critical sections of code. It can become very costly if those allocations occur in tight loops.
The new language feature means that async methods may return other types in addition to Task, Task<T> and void. The returned type must still satisfy the async pattern, meaning a GetAwaiter method must be accessible. As one concrete example, the ValueTask type has been added to the .NET framework to make use of this new language feature:
public async ValueTask<int> Func()
{
await Task.Delay(100);
return 5;
}
NOTE: You need to add the NuGet package System.Threading.Tasks.Extensions in order to use the ValueTask<TResult> type.
A simple optimization would be to use ValueTask in places where Task would be used before. However, if you want to perform extra optimizations by hand, you can cache results from async work and reuse the result in subsequent calls. The ValueTask struct has a constructor with a Task parameter so that you can construct a ValueTask from the return value of any existing async method:
public ValueTask<int> CachedFunc()
{
return (cache) ? new ValueTask<int>(cacheResult) : new ValueTask<int>(LoadCache());
}
private bool cache = false;
private int cacheResult;
private async Task<int> LoadCache()
{
// simulate async work:
await Task.Delay(100);
cacheResult = 100;
cache = true;
return cacheResult;
}
NOTE: As with all performance recommendations, you should benchmark both versions before making large-scale changes to your code. Feel free to use BenchmarkDotNet library for the purpose that can be found in GitHub repository here.
Expression-bodied Members
With C#6 we’ve got expression-bodied members, which allowed us to express simple methods using lambda-like syntax. However, this new syntax was limited to methods and read-only properties. With the first-ever community contribution to C#, C#7 expands this syntax to cover constructors, finalizers, and property accessors.
If we take the property example we had before, containing our throw expression as part of property set accessor, we can now write it as:
public object SomeProperty
{
get => _someProperty;
set => _someProperty = value ?? throw new ArgumentNullException();
}
I won't bother with examples for constructors or finalizers; the main documentation is pretty clear on those and I am not convinced the syntax will be used very often in those cases. Constructors are rarely so simple that the expression-bodied syntax makes sense, and finalizers are so rarely needed that most of us will not get an opportunity to write one at all, expression-bodied or otherwise.
Throw expressions
It is easy to throw an exception in the middle of an expression: just call a method that does it for you! But in C# 7.0 we are directly allowing throw as an expression in certain places:
class Person
{
public string Name { get; }
public Person(string name) => Name = name ?? throw new ArgumentNullException(nameof(name));
public string GetFirstName()
{
var parts = Name.Split(" ");
return (parts.Length > 0) ? parts[0] : throw new InvalidOperationException("No name!");
}
public string GetLastName() => throw new NotImplementedException();
}
The future directions
The new features have been added constantly to the language. Microsoft and the community are working not only on 7.2 but also version 8 of C#. The best resource to track all the future features or suggestions would be GitHub page here. My next topic will be dedicated to the new features in C# 7.1 which are exciting in itself. Stay tuned!
Part 2. The theory
.NET Framework is a software framework developed by Microsoft that runs primarily on Microsoft Windows. It includes an extensive class library named Framework Class Library (FCL) and provides language interoperability (each language can use code written in other languages) across several programming languages. Programs are written for .NET Framework execute in a software environment (in contrast to a hardware environment) named Common Language Runtime (CLR), an application virtual machine that provides services such as security, memory management, and exception handling. (As such, computer code written using .NET Framework is called "managed code.") FCL and CLR together constitute .NET Framework.
According to Figure 1, it wasn’t much, but I know Enterprise-level systems written in .NET 1.1 Microsoft has started .NET Framework development in the late 90s and they did a great job. It was revolutionary (to some extent). I remember reading Fritz Onion’s book “Essential ASP.NET” and the way he admired the new approach in web development using this platform. Fortunately, Microsoft didn’t stop at this step, and in 2006 they released 2.0. It has lots of exciting changes in Generics, Static classes, Attributes, Partial types, etc., e.g., the features, without which I can’t imagine modern development.
I think it was a little bit too much for the intro and the aim is not to describe all the changes in all .NET Framework editions. I think Version 6 was a real break-through, i.e., exactly that release where Microsoft has shifted towards open-source and introduces compiler-as-a service, aka “Roslyn” (please see Figure 1 for the reference). Traditionally, compilers are black boxes – source code goes in one end, magic happens in the middle, and object files or assemblies come out the other end. As compilers perform their magic, they build up a deep understanding of the code they are processing, but that knowledge is unavailable to anyone but the compiler implementation wizards. The information is promptly forgotten after the translated output is produced. For decades, this worldview has served us well, but it is no longer sufficient. Increasingly we rely on integrated development environment (IDE) features such as IntelliSense, refactoring, intelligent rename, “Find all references,” and “Go to definition” to increase our productivity. We rely on code analysis tools to improve our code quality and code generators to aid in application construction. As these tools get smarter, they need access to more and more of the deep code knowledge that only compilers possess. This is the core mission of Roslyn: opening up the black boxes and allowing tools and end users to share in the wealth of information compilers have about our code.
The .NET Compiler Platform ("Roslyn") provides open-source C# and Visual Basic compilers with rich code analysis APIs. You can build code analysis tools with the same APIs that Microsoft is using to implement Visual Studio! It is hard to underestimate open-source approach, but if you would ask ‘what is it for?’, I’d refer you to an excellent blog-post by Alex Turner “Use Roslyn to Write a Live Code Analyzer for Your API.”
The next stop is .NET Core. I believe it was the most long-awaited feature and the platform overall. The journey has started with project “Mono” (the first attempt to make .NET platform-agnostic) and found its logical resolution in .NET Core, where the platform was completely rewritten from ground-up (as Microsoft and partners state) and not .NET Framework alternative (as Wikipedia definition says, even though it shares some of the .NET Frameworks API’s).
.NET Core is the next generation of ASP.NET that provides a familiar and modern framework for web and cloud scenarios. It includes the next version of ASP.NET MVC, Web API, Web Pages and SignalR. It is a high-performance and modular design and supports full side by side to make it seamless to migrate from on-premise to the cloud. These products are actively developed by the ASP.NET team in collaboration with a community of open source developers.
The following characteristics best define .NET Core:
- Flexible deployment: Can be included in your app or installed side-by-side user- or machine-wide
- Cross-platform: Runs on Windows, macOS, and Linux; can be ported to other operating systems. The supported Operating Systems (OS), CPUs and application scenarios will grow over time, provided by Microsoft, other companies, and individuals
- Command-line tools: All product scenarios can be exercised at the command-line
- Compatible: .NET Core is compatible with .NET Framework, Xamarin, and Mono, via the .NET Standard
- Open source: The .NET Core platform is open source, using MIT and Apache 2 licenses. Documentation is licensed under CC-BY. .NET Core is a .NET Foundation project
- Supported by Microsoft: .NET Core is supported by Microsoft, per .NET Core Support
Attending different conferences (as a speaker and a guest) I hear the same question quite often “What does it mean for Developers? Will Microsoft stop be supporting .NET Framework?” etc. In short - no. These are two different paradigms, development models, and frameworks that can be used all together though. You may ask, how is that possible? Well, there is a leverage you may never be heard about, which is “.NET Standard”.
.NET Standard solves the code sharing problem for .NET developers across all platforms by bringing all the APIs that you expect and love across the environments that you need: desktop applications, mobile apps & games, and cloud services:
- .NET Standard is a set of APIs that all .NET platforms have to implement. This unifies the .NET platforms and prevents future fragmentation
- .NET Standard 2.0 will be implemented by .NET Framework, .NET Core, and Xamarin. For .NET Core, this will add many of the existing APIs that have been requested
- .NET Standard 2.0 includes a compatibility shim for .NET Framework binaries, significantly increasing the set of libraries that you can reference from your .NET Standard libraries
- .NET Standard will replace Portable Class Libraries (PCLs) as the tooling story for building multi-platform .NET libraries
Sounds good, but what does it mean for me?
The .NET platform was forked quite a bit over the years. On the one hand, this is actually a really good thing. It allowed tailoring .NET to fit the needs that a single platform wouldn’t have been able to. For example, the .NET Compact Framework was created to fit into the (fairly) restrictive footprint of phones in the 2000 era. The same is true today: Unity (a fork of Mono) runs on more than 20 platforms. Being able to fork and customize is an important capability for any technology that requires a reach. But on the other hand, this forking poses a massive problem for developers writing code for multiple .NET platforms because there isn’t a unified class library to target.
There are currently three major flavors of .NET, which means you have to master three different base class libraries in order to write code that works across all of them. Since the industry is much more diverse now than when .NET was originally created it’s safe to assume that we’re not done with creating new .NET platforms. Either Microsoft or someone else will build new flavors of .NET in order to support new operating systems or to tailor it for specific device capabilities. This is where the .NET Standard comes in (see Figure 2):

Figure 2. .NET Standard library
With .NET Standard 2.0, Microsoft focuses on compatibility. In order to support .NET Standard 2.0 in .NET Core and UWP, they’ll be extending these platforms to include many more of the existing APIs. This also includes a compatibility shim that allows referencing binaries that were compiled against the .NET Framework.
NOTE: From what I heard at the latest VSLive! Conference this year, Microsoft would be focusing equally on .NET Framework, .NET Core and Xamarin without any preferences among them. It means that the new APIs will be delivered equally quick and more or less simultaneously for all of them.
In .NET Core apps (either ASP.NET Core apps or Console apps, as of today) there are new possibilities like being able to run your app (like an ASP.NET Core app) on top of the .NET Core Platform or on top of the traditional .NET Framework 4.5.x+ which is critical for many enterprise apps that still might not have all the libraries/components compiled for .NET Core available (custom or third party). To do so, you can use so-called “Target platform monikers” (TFMs). The Target Framework Monikers are IDs of the type framework + version that you can target from your apps in .NET Core and ASP.NET Core. As examples (there are more), you can use:
- “netcoreapp2.0” For .NET Core 2.0
- “net461”, “net47” for .NET Framework versions
- "portable-net462+win8" for PCL profiles
- "dotnet5.6", "dnxcore50" and others, for older .NET Core preview versions (Before .NET Core 1.0 RTM and .NET Core 2.0 were released)
- “netstandard1.5”, “netstandard2.0”, etc. for .NET Standard Platform monikers.
You can also use pre-compiler directives to target traditional framework:
#if NET462
// access something that requires traditional .NET Framework (like Windows-related stuff)
#endif
Closing
It is recommended to use .NET Core whenever is possible for your requirements (as it is cross-platform) and full .NET Framework (which might only work on Windows depending on the APIs being used, plus full .NET framework is heavier) only when you have no other choice because the API you want to use doesn’t exist in .NET Core.
Take into account that the purer .NET Core you use, the easier you’ll have it for modern scenarios. Not just cross-platform across Linux and Windows but also environments on Docker containers which are a lot better/lighter when running on pure .NET Core images than full Windows Containers.
Sure, if your .NET Framework libraries don’t use any particular Windows API, it might also run okay on Linux, but, the more libraries you have on .NET Standard Library and .NET Core projects, the better for the future.🙂
Don’t know who is Fritz Onion? Fritz is a co-founder of Pluralsight where he serves as the Content Advisor. Fritz is the author of the book 'Essential ASP.NET' published by Addison Wesley.
References: