Scalability and resiliency are important quality attributes for any Enterprise Application. When it comes to scalability, Azure has multiple options to achieve the goal. This article can be helpful not only for the beginners who want to familiarize themselves with different scalability tactics but also for the professionals looking to broaden their horizons around this Architectural aspect. I will be considering all the scalability means provided by Azure first and then, as a bonus, we’ll go a little bit beyond the cloud in the second part of this article.
App Services scalability (PaaS)
This is probably the easiest case. No matter where you deploy it, the scaling is a relatively simple task. The very first options that come into the mind is a PaaS (Platform-as-a-Service) offering, which is Azure App Service. It is easy to automate the release process using Azure DevOps (I was considering it in previous topics) and manage.
- Scale up (vertical scalability)
Scaling vertically (up/down) means adding resources to (or removing resources from) a single node, typically involving the addition of CPUs, memory or storage to a single computer:
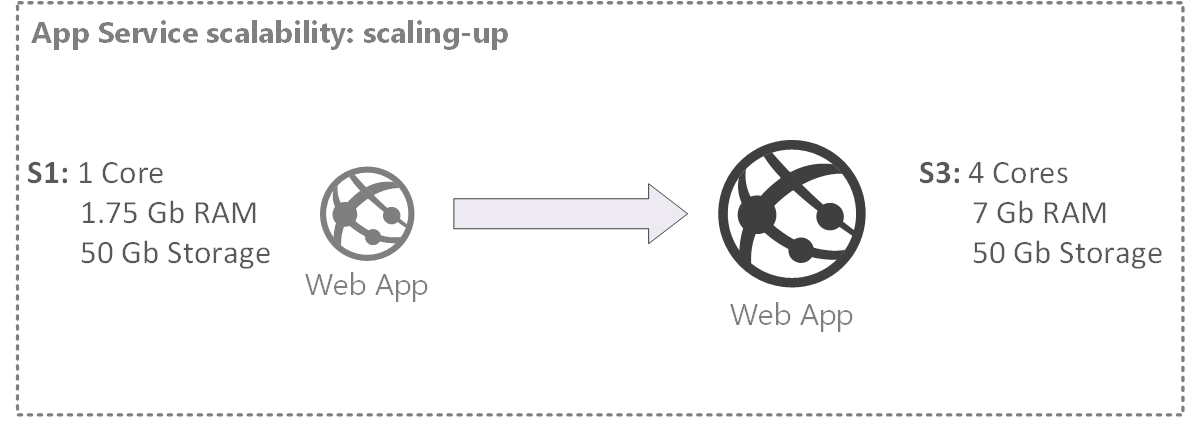
Figure 1. Web application scale-up (to S3 tier)
- Scale-out (horizontal scalability)
Scaling horizontally (out/in) means adding more nodes to (or removing nodes from) a system, such as adding a new computer to a distributed software application:
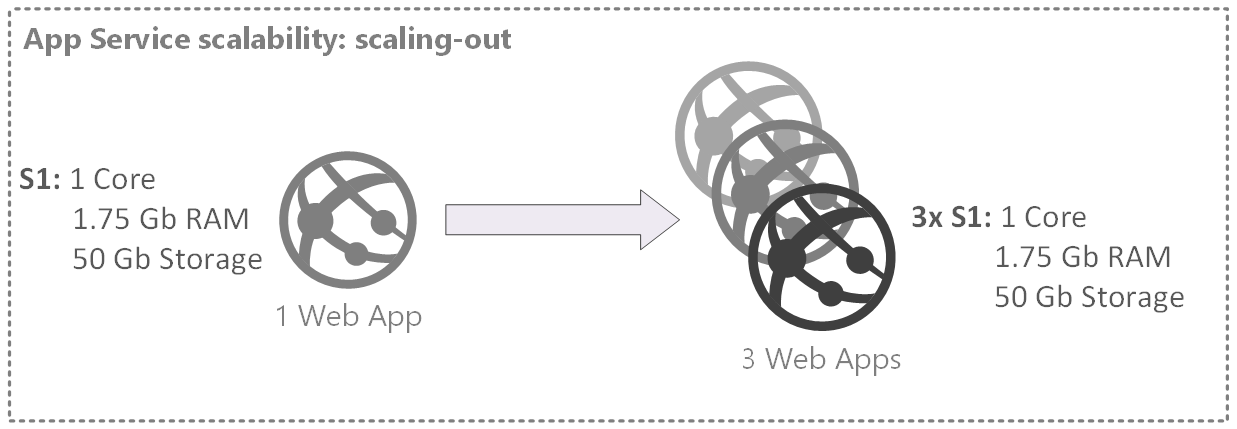
Figure 2. Web application scale-out
Both options serve their needs, although, scale-out is more ‘automation friendly’ and can be configured from App Service dashboard (Settings -> Scaleout -> Enable autoscale). You can scale based on a metric (depending on the app load that affects RAM/CPU) or scale to a specific instance count right away. In both cases, the traffic between instance is distributed through the Internal Load Balancer (ILB).
Caveats:
- Bear in mind that along with Azure, App Service is a multitenant environment (in full sense of this word). It works on top of VM behind the scenes, shared with multiple Azure tenants
- When using ‘Scale-out’ whether it’s based on metrics or the instance count increased to a specific number, keep an eye on the instances count as they add up to the cost of the service (so the monthly bill is not a surprise to you). Do not forget about implementing ‘scale-in’ rules (if you scale out based on a metric) as the instance count is not reduced on its own
- One more word about isolation. The multi-tenant nature of the App Service poses certain constraints you have to put up with (like networking specifics). If it is a concern, you may want to consider some other options like purchasing an Isolated instance type or deploy your app to a VM. These options are not equal so it’ll cost you efforts and money. We’ll consider VM’s next.
Virtual Machines scalability (IaaS)
Scaling up a virtual machine (VM) is also an option, however, you won’t find a familiar word in the VM settings as it’s called ‘Sizing’ in VMs realm. Just like in the case with App Services ‘tiers’, the VMs sizes are predefined (there is no way you can assemble a custom VM configuration)
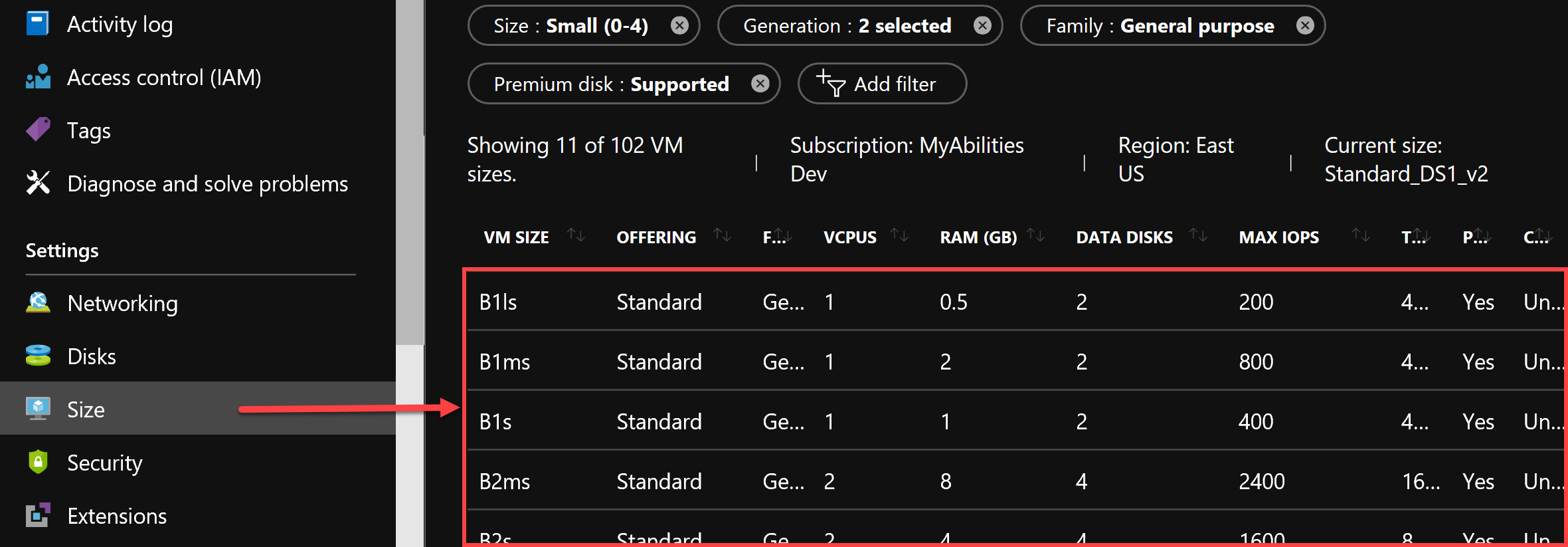
Figure 3. VM Sizing (scaling-up, or vertical scalability)
Just like App Services, vertical scalability can be automated using PS scripting.
There is a bit different approach toward horizontal scalability. In the case with VMs, so-called Scale sets are used. VM scale sets let you create and manage a group of identical, load balanced VMs. The number of VM instances can automatically increase or decrease in response to demand or a defined schedule. Scale sets provide high availability to your applications and allow you to centrally manage, configure, and update a large number of VMs.
There are options how you can balance the load between the VMs in the Scale set: you can choose either a Load Balance or Application Gateway (both work well for the purpose).
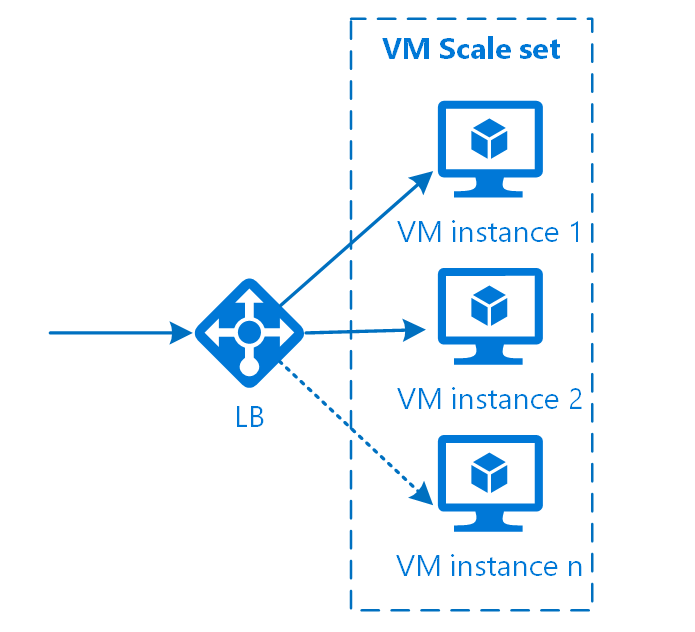
Figure 4. VM Scale set
The benefit to going with VM is quite obvious. Comparing to App Service (which is PaaS) it provides you more freedom in configuration and better app isolation, in case if it’s a concern. VM Scale set is created along with Virtual Network (VNet) and a Network Security Group (NSG) attached to it, so has everything to support a proper level of isolation out of the box.
Caveats:
- No all the VM type available in every Azure region, so when automating, keep the regional specifics in mind
- Choose paired regions for HA support
- The OS for the VM is the scale set cannot be changed. The size change for the scale set will affect all instances in the given set
Azure Service Fabric
Azure Service Fabric (ASF) is a distributed systems platform that makes it easy to package, deploy, and manage scalable and reliable microservices and containers. Service Fabric also addresses the significant challenges in developing and managing cloud native applications.
Behind the curtains, ASF relies on VMs. Well, as we learnt, almost everything in the cloud relies or based on VMs, even Application Gateways and Load Balancers. It means that for the scalability purposes the ASF utilizes Scale sets we already familiar with. When you deploy your first ASF cluster, you’ll notice that along with VMs, you’ve got an Internal Balancer (ILB) deployed that supposed to distribute the load between the VMs in a Scale set:
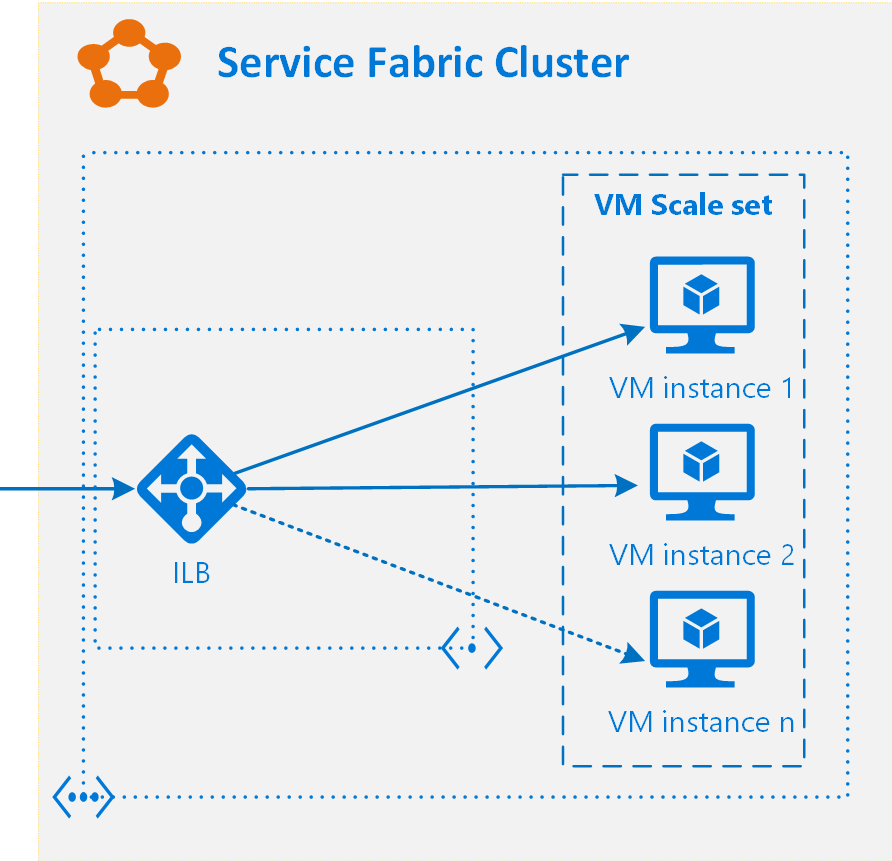
Figure 5. ASF Cluster scalability
There are many benefits if you go ahead with ASF:
- Azure portal makes it easy to create and manage clusters
- Use of Azure Resource Manager allows easy management of all resources used by the cluster as a unit and simplifies cost tracking and billing
- A Service Fabric cluster is an Azure resource, so you can model it like you do other resources in Azure
- Service Fabric coordinates with the underlying Azure infrastructure for OS, network, and other upgrades to improve security, availability and reliability of your applications
- Azure provides integration with Azure diagnostics and Log Analytics
- Azure provides built-in auto-scaling functionality due to Virtual Machine scale-sets. In on-premises and other cloud environments, you have to build your own auto-scaling feature or scale manually using the APIs that Service Fabric exposes for scaling clusters
- ASF provides multiple development models suitable for any scenario
- ASF SDK allows extending the base functionality receiving whatever functionality or integration you may need
- ASF is very good at testing. You can run ASF nodes locally in a reduced capacity to test your app
- What’s interesting, you are free to choose any cloud provider to host your cluster
Caveats:
- As in the case with VMs, keep the regional specifics in mind
- Choose paired regions for HA support
- In the world of quorum-based platforms like Azure Service Fabric, the number 3 is extremely important, because decisions are made by the majority. For Geo-HA we need at a minimum of 3 regions, each containing a minimum of 3 nodes. Three, because a quorum is satisfied by 2 out of 3. Otherwise, the cluster is degraded and becomes read-only
- Building a Geo-redundant solution based on ASF is a challenging task (considering a quorum nature of ASF).
I will be considering ASF and a Service Mesh in more details in my following topics.
Azure Kubernetes Services (AKS)
Kubernetes is a rapidly evolving platform that manages container-based applications and their associated networking and storage components. The focus is on the application workloads, not the underlying infrastructure components. Kubernetes provides a declarative approach to deployments, backed by a robust set of APIs for management operations.
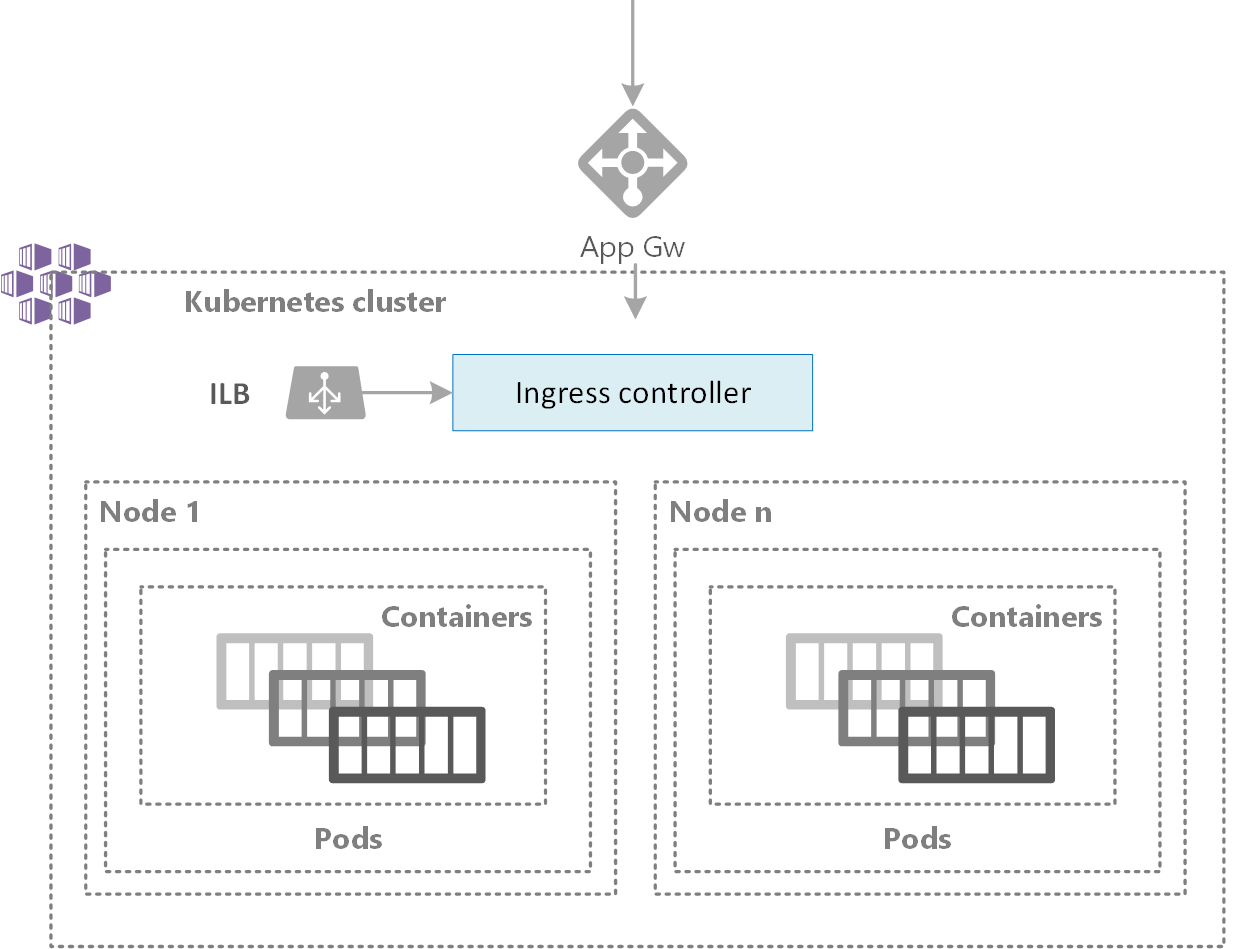
Figure 6. AKS Cluster scalability
To adjust to changing application demands, such as between the workday and evening or on a weekend, clusters often need a way to automatically scale. AKS clusters can scale in one of two ways:
- The cluster autoscaler watches for pods that can't be scheduled on nodes because of resource constraints. The cluster automatically then increases the number of nodes
- The horizontal pod autoscaler uses the Metrics Server in a Kubernetes cluster to monitor the resource demand of pods. If a service needs more resources, the number of pods is automatically increased to meet the demand
Both the horizontal pod autoscaler and cluster autoscaler can also then decrease the number of pods and nodes as needed. The cluster autoscaler decreases the number of nodes when there has been unused capacity for a period of time. Pods on a node to be removed by the cluster autoscaler are safely scheduled elsewhere in the cluster.
Scaling operation is K8s cluster is relatively simple:
az aks update --resource-group myResourceGroup --name myAKSCluster \
--enable-cluster-autoscaler --min-count 1 --max-count 3
NOTE: I don’t explain the basics and the command meaning here. For more information about Kubernetes and fundamental operations, see my previous article here.
Caveats:
The cluster autoscaler may be unable to scale down if pods can't move, such as in the following situations:
- A pod directly created and isn't backed by a controller object, such deployment or replica set
- A pod disruption budget (PDB) is too restrictive and doesn't allow the number of pods to be fall below a certain threshold
- A pod uses node selectors or anti-affinity that can't be honoured if scheduled on a different node
To be continued….